Automated Fault Tolerance using the Circuit Breaker Pattern
In this post, we will discuss a new technique called “circuit breakers” to make the site more fault tolerant. Circuit breakers are a solution to the problem of quickly detecting and remediating the situation when an external dependency starts failing.
Problem #
The diagram below shows at a high level how the Teachers Pay Teachers site works.
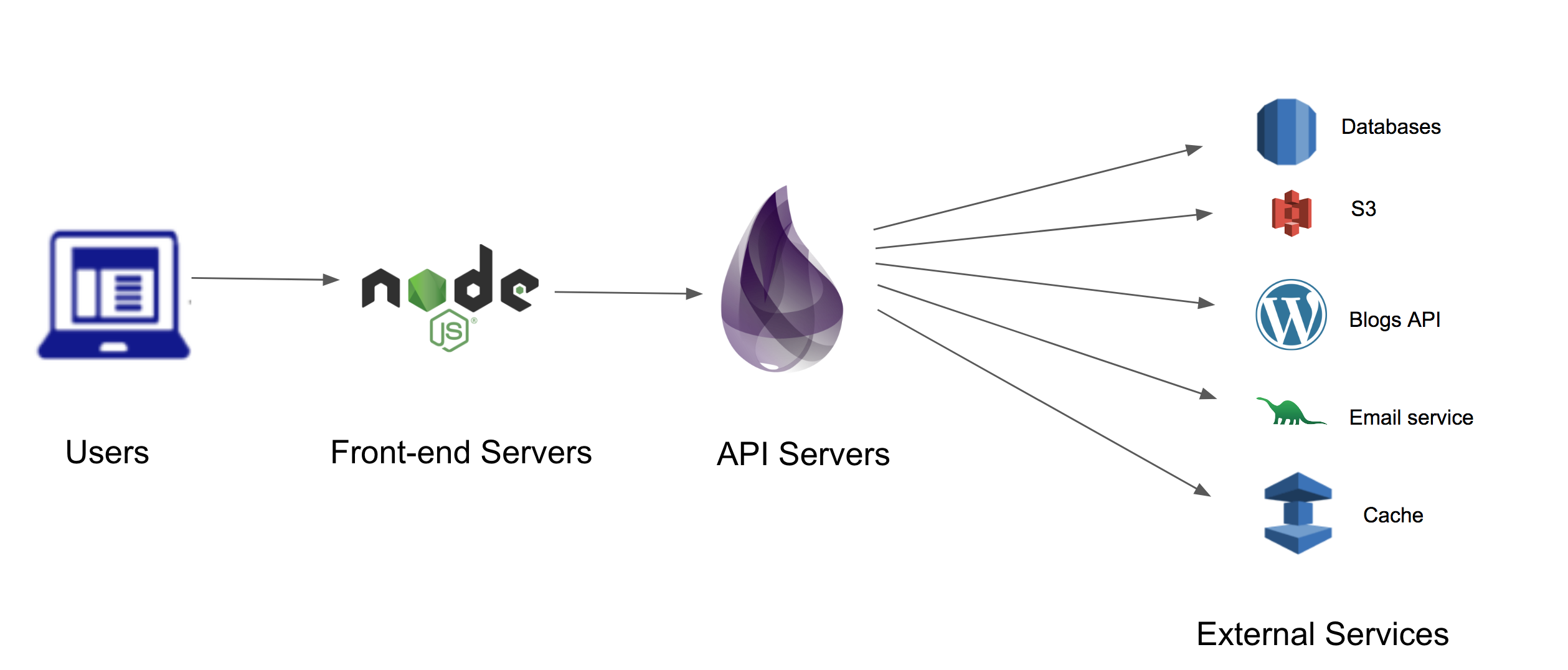
Our users are educators browsing the site for resources they use in the classroom. Their requests are funneled through the front-end servers that run Node.js. The content is powered by an API written in Elixir using the Phoenix framework. The API has dependencies on lots of external systems, from databases and cache to several third party APIs.
In a perfect world, systems would never fail and site reliability is not a problem to be solved. In reality we don’t live in an ideal world and things do fail. Systems do go down. For example, requests to our search results page require running a heavy database query to get some secondary content. When the database is under load, this query can time out, causing the whole page to fail. Another example is our mobile app homepage uses the Wordpress API for a small portion of its content. When the Wordpress API was updated, our whole mobile homepage failed to load. It would be easy to find several other examples following a similar dependency pattern.
Handling Failures #
We do not have control over our external dependencies. Also, while writing software it is not feasible to predict all run-time variations. Failures are inevitable. Preventing them altogether is not realistic. The question is how to handle failures. What can we do when a system is down or unresponsive? At a very high level there are two approaches to this problem:
- We respond manually after we detect the failure. There are certainly ways to optimize here - for example, we put content that comes from external systems behind feature flags that we can turn off quickly. This is how we handled the Wordpress issue. At TpT, feature flag deploys take less than 30 seconds. The MTTR here would be 30 seconds plus the time taken by a human to act.
- We program our system to automatically respond and gracefully degrade using circuit breakers. This approach needs no human intervention. We’ll be focusing on this approach below.
Introducing Circuit Breakers #
The circuit breaker pattern automatically detects unhealthy services and blocks requests to them. We have implemented this pattern by extending our existing feature flags logic. We have feature flags in place to toggle requests to certain services. In order to detect unhealthy services, we need a way to store their health status. We store the status of each request to a service in Cachex in a simple list. We store 1 for success and 0 for failure as shown below. The TTL on the cache defaults to 60 seconds. This timeout is configurable for each feature.
if not circuit_break(service_name) do # if circuit is not broken
try do
result = call_service()
update_request_status(1, service_name) # set success in Cachex
result
rescue # service errored out
err ->
update_request_status(0, service_name) # set failure in Cachex
end
endWhen a new request comes in, we compute error rate from the stored request statuses and break the circuit if error rate exceeds a predefined threshold.
def circuit_break(service_name) do
request_statuses = Cachex.get(:api, service_name)
history_size = length(request_statuses)
# compute error rate
error_rate = Enum.count(Enum.filter(request_statuses, &(&1 == 0))) / history_size
if error_rate < error_threshold do
false # don’t circuit break
else
true # circuit break
end
endFor each feature we also define a minimum and maximum size for history of request statuses since we don’t want to break the circuit too soon or flood the cache with too much data. When the circuit is not broken, the request proceeds and stores its status in cache as shown in the first block of code. When the circuit breaks, all calls to the service are blocked until the cache expires. The API cleanly sends a response back to the front-end with downgraded content. The front-end does not break and is able to load the page with the content received. This behavior is called graceful degradation.
Graceful Degradation #
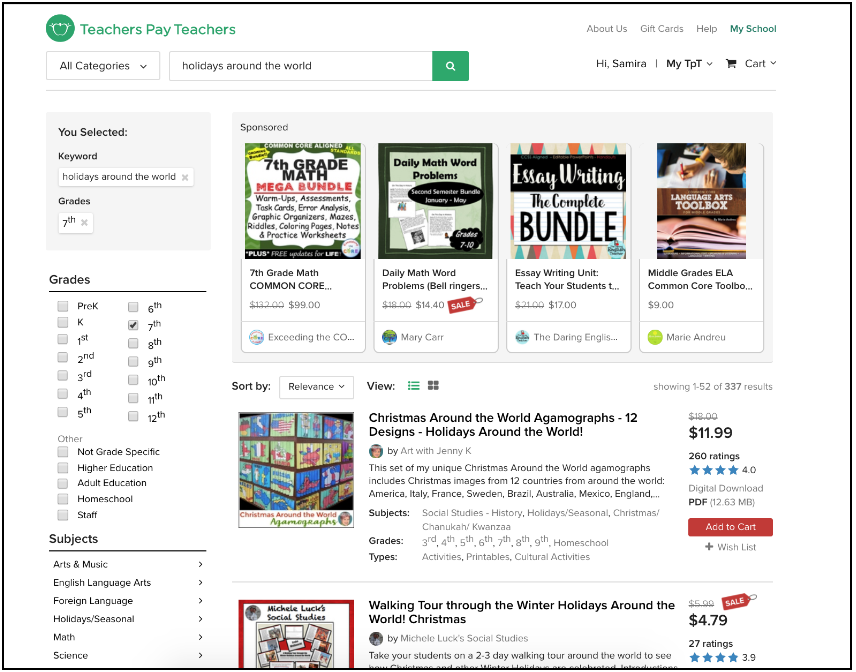
We will illustrate graceful degradation with an example. Below is a screenshot of our search results page under normal conditions. Notice that above the search results we display a set of sponsored items.
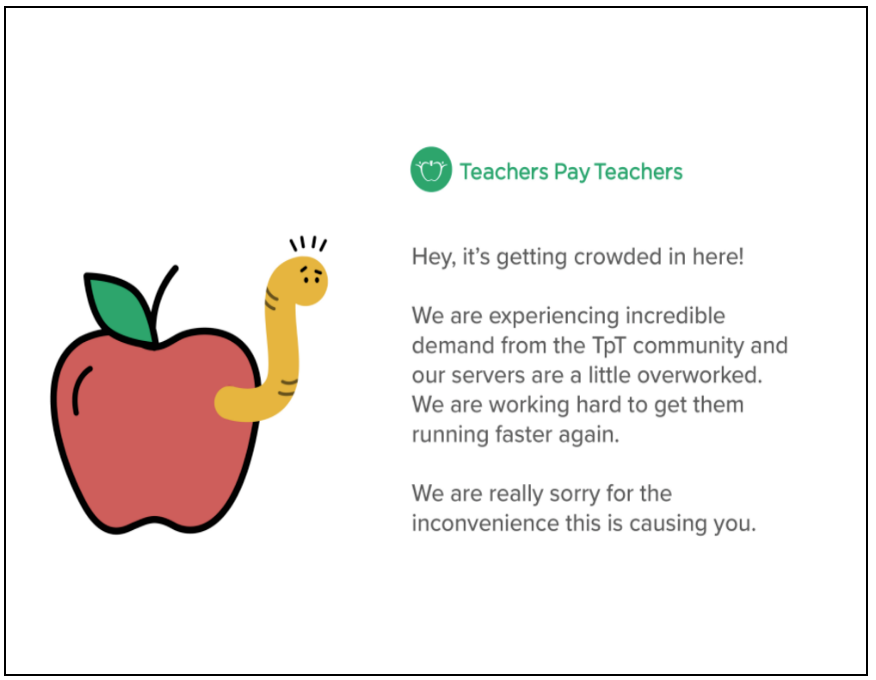
Now suppose the query retrieving sponsored items times out due to high database load. Before we implemented the circuit breaker pattern, this would result in an error page.
Now when the error rate is high on sponsored items we simply break the circuit on that feature alone and return the rest of the content on the page.
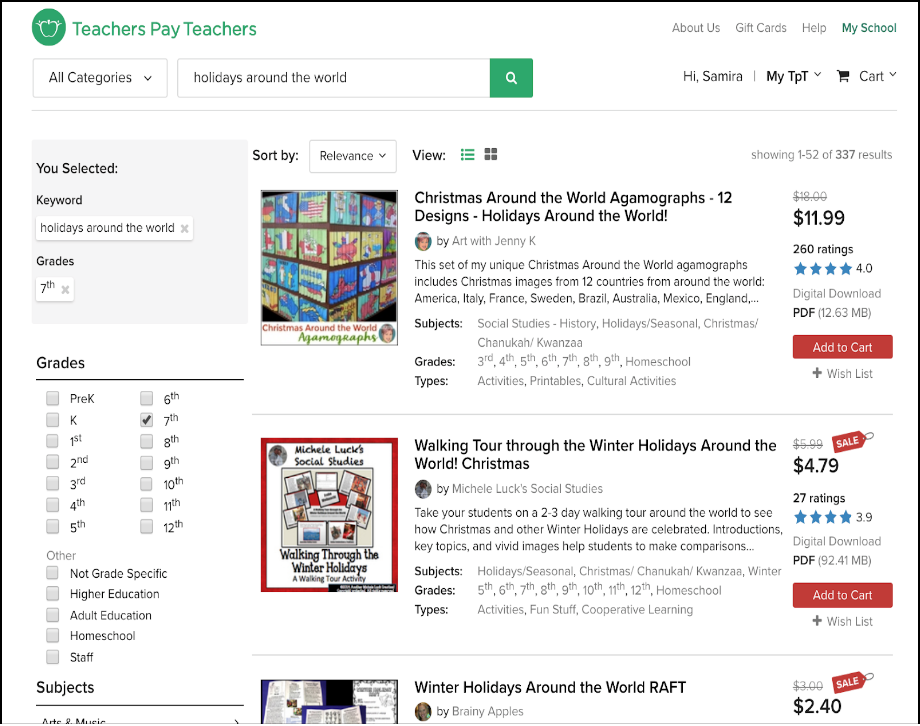
In other words, if the user requested for content X, Y and Z and Y is seeing a high error rate, we return X and Z instead of returning nothing. We have enabled the circuit breaker on Wordpress requests as well in our mobile homepage and many other features that have a high probability of failure.
Graceful degradation does not require circuit breakers and is possible with proper exception handling. The circuit breaker pattern is an optimization on exception handling in that it proactively turns off degraded features. This prevents hammering a system that is already under stress (in our example, the database) and allows it to recover faster.
Trade offs #
We ran into cache contention issues with Cachex and later moved to ETS. It still requires each API server to locally store request status data and can result in inconsistent behavior across servers. Using external storage such as Memcached or Redis would ensure the servers are in sync, but introduce another point of failure. Also, it could cause all servers to block a feature in a case where only one server is degraded and error threshold is low.
We currently determine error thresholds heuristically which might be too low or high. An alternative is to set dynamic error thresholds for each feature based on its historical behavior. We could detect anomalous error rates from comparable past time periods. This would result in fewer false negatives but requires significant investment of time and resources.
Final Thoughts #
Circuit breakers are not suitable for all situations and should definitely not be used on the very core features of the site. For example, if our transactional database cluster is down and we are unable to fetch any user or product data, then we would have no choice but to serve an error page to users.
We are not in a perfect state yet but the above described basic circuit breaker pattern has been effective in mitigating user impact during unforeseen failures. Special shoutout to my coworker Jeff Martin for working with me on the implementation.
Do you have questions or ideas on fault tolerance? Talk to us in the comments section!