Rock Like a Sphinx: Driving Solid Search Infrastructure at TpT

The TpT team is always working to keep our search page reliable, fast, and relevant. For the past five years we’ve been working on our search infrastructure to serve all of those needs simultaneously without deprioritizing any of them. How is this done? It’s time to take a peek underneath the hood.
The Search for a Search Engine #
Originally we were looking for a search engine to replace MySQL-based search. At the time, our catalog had around 500,000 products, and the MySQL-based solution was no longer scaling. So the challenge was to find a solution that allowed us to make our search infrastructure change seamless, low effort, and most importantly, easy to maintain in supporting the future growth of the search index.
We were looking for third-party software that had the following attributes:
- Easy to install and configure
- Integrates seamlessly into the existing system
- Maintainable, including reasonable index times
- Speedy queries for a good user experience
- Easy to query and has rich relevancy manipulation tools
As the search engine market is not very big, we quickly narrowed the field down to three: Apache Solr, ElasticSearch, and Sphinx.
As you may have noticed, we chose Sphinx. This was for several reasons:
First, it’s very easy to install and configure. It doesn’t require any additional dependencies. It’s a native app written in pure C.
Second, it is easy to query. The Sphinx query language is SQL-like and uses the MySQL protocol. So on the developer’s side, there’s no need to learn a lot of syntax to run your first search, it’s just good old SQL. It is also easy to find or write a client in a wide variety of programming languages, as almost all of them support running SQL queries and have MySQL drivers. While we use the MySQL protocol, a RESTful API is also available in the latest beta version.
Third, it’s extremely low-effort to spin up a search service based on Sphinx as it supports extremely fast indexing process of data you may already have. We were able to index our 500,000 products – titles, full descriptions, and all metadata – in just 2 minutes (!) and were ready to serve search queries. Today, with over 5X growth and the product catalog now in the millions, a full reindex still takes just 7 minutes.
Reliable: The Power of Immutability #
Sphinx supports two types of indexes: mutable and immutable. A mutable index is like a SQL table where you have to read, insert, or delete your data. With a mutable index, you have to constantly push or send the data over to the mutable indexer process yourself, inserting data into the index to keep it up to date. This is also the ElasticSearch and Solr approach. The benefit of a mutable index is this results in the shortest time from any change made to your data and its appearance in the search index. So if an app is pretty sensitive to index freshness, the mutable index is the way you may go.
An immutable index is a read-only dataset. It is created by an indexer tool and can’t be changed until the next version of the index is created. Rather than pushing data to the indexer process, the indexer process pulls in the documents to be indexed on an interval. Immutability is one of the key features of Sphinx. The downside of an immutable index is the index can’t be refreshed on every change to app data, so you have to allow for about 5 minutes of delay for changes to be replicated to the search index.
Drawbacks of Mutability #
While conceptually easy-to-grasp – insert a document and voilà, the search index now is able to search over the new document too – this also greatly complicates search infrastructure. With complexity comes also a higher likelihood of failure and increased difficulty in debugging.
Specifically, with a push-based model, a queue is usually necessary somewhere in the pipeline to buffer inserts so that the ingestion process won’t be overloaded. Many of you may be familiar with this scenario if you run an ElasticSearch / ELK-stack for searching your logs. There’s the upside of getting recent logs searchable with little delay; but also the downside of running into problems with ingestion being overloaded or index delays.
Here’s a typical flow:

In addition to queuing, you’ll also need to be careful that you are catching all of the possible updates to your catalog and are properly notifying the index process. If the queue goes down or some case is missed, say deactivated products or updates to a subject field, it may be difficult to trace exactly which updates were missed. This is difficult to deal with, and often forces a full reindex. The incremental updates are slow, so a full reindex on the same amount of data could easily take hours or even days.
Last, for Sphinx, the incremental index type also does not have all the functionality of a full-reindex, and there are some restrictions on what kind of data can be updated.
Immutable Indexes #
Immutable indexes are filled with data using a built-in indexer tool which reads SQL statements from your config file. All of the catalog data is read together in bulk at maximum speed. This data is then used to create index files. They are read-only, or immutable, and this is the key. After a full reindex has occurred, we have an immutable dataset as a result. It’s reliable by design. If an index process completed successfully, you can’t break the index, you just read from it. And for a catalog search, that’s all you need, right? We get an all new search dataset after each reindex, fresh and healthy. No garbage collection, no optimisation, and no defragmentation required.
You may wonder at this point about the load on our databases if Sphinx is querying the full catalog data all at once. In the past, this load on read-replicas for our databases was acceptable, but we’ve grown to the point where Sphinx now reads from a dedicated replica. This replica supports a variety of bulk tasks and is not in the render path for our website users. So our dataflow looks something like this:
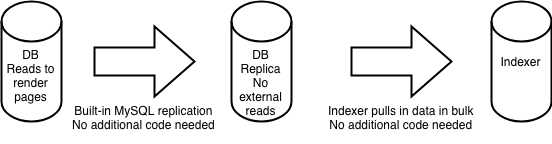
Immutable indexes also have a few more benefits. Because the index is immutable, it is also easy to scale out reads horizontally by replicating the index to as many servers as needed. At current index sizes, while we have the capability, we do not yet need to use sharded indexes distributed to different machines, and each read server has the full search index. Since we’re on virtual servers on AWS, we’ll be able to avoid distributing the index and scale up by simply switching to larger instance sizes as needed.
Additionally, because of the fast speed of indexing, we’re able to run full reindexes once an hour with plenty of room to further increase the frequency. If we run into temporary blips, the next full reindex can often clear up any mistakes. In the infrequent case that we want to manually trigger a full reindex, we also have no hesitation as it is fast to run.
Last, while we could also run the full reindex more frequently, a simple way we keep our seach index fresh is by also practicing delta indexing every 10 minutes to pick up changes with less lag. So by doing this we have fairly fresh search data with all of the benefits of an immutable index.
Conclusion #
While Sphinx has not had as much traction as other search engines, we find Sphinx’s model of immutability to be more reliable and functionally superior. It was a short and easy process to get Sphinx up and running to serve our searches. We have configured it to run its own indexer job and were ready to go. TpT has served over a billion searches reliably and correctly, with very few operational issues, and quick recovery in the rare cases where there are. Overall, Sphinx has been a rock-solid piece of our infrastructure and has allowed us to focus a majority of our time on relevancy. Stay tuned for future posts about how we build on top of Sphinx for both fast and relevant search.