From 10 Hours to 10 Minutes: Scaling Release Automation at Teachers Pay Teachers
It used to take one engineer 10 hours to release new code to teacherspayteachers.com. Now it takes 10 minutes. We simplified and automated the release process with a set of steps that decentralized the process, all while introducing higher confidence in the code we release. For us, this was a prerequisite step to shifting our development process toward continuous delivery.
Where we started #
Our release process used to looked like this:
Our branching strategy was similar to Gitflow.
We had a Release Manager.
The Release Manager would review all code going into a release.
Only the Release Manager could merge code for release.
There were frequent conflicts.
There were minimal unit tests.
Releases had to be approved by a manual QA team, which often required multiple cycles back and forth between them and engineers due to the lack of automated testing.
Deploying the release involved a complex set of individual steps, each requiring manual intervention, information gathering, and typing.
We had good monitoring of our production infrastructure.
When we looked at how long different parts of the release process took, we found we were spending the time roughly as follows:
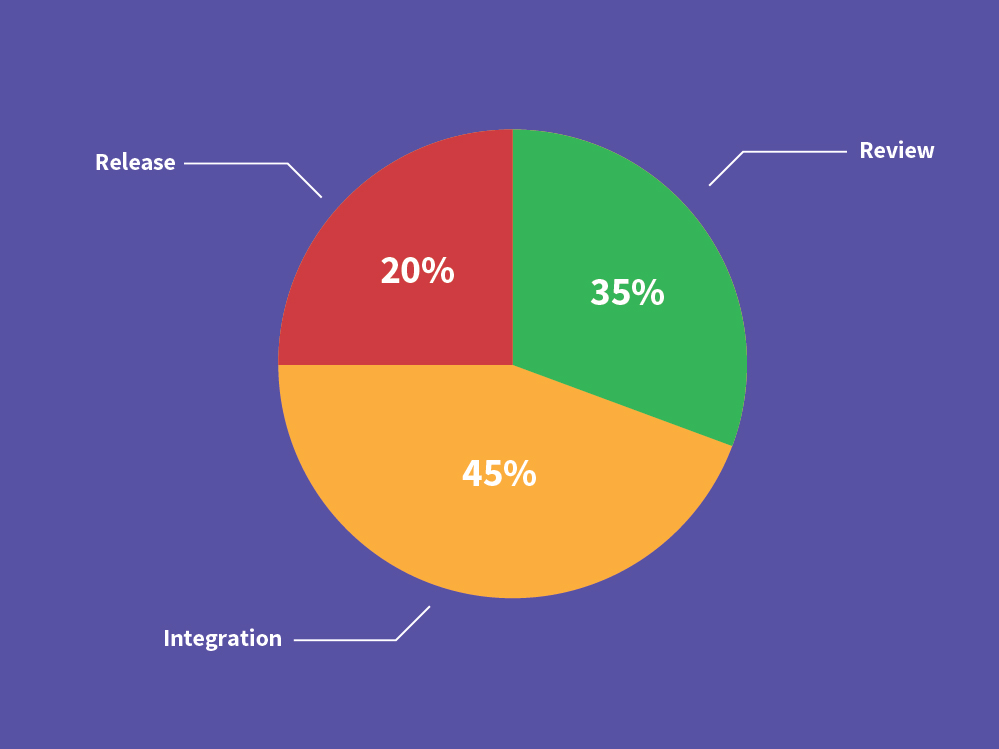
Because releases took so much effort, it was tempting to do them less often and release features in big chunks instead of incrementally. Our Engineering and Product teams decided go the other direction instead: we wanted to drastically cut our time to get features to users. We wanted to move to continuous delivery.
Metrics #
When we started thinking about continuous delivery, we realized that features waited a long time to get released after code review. So we started tracking the time from "ready for code review" to “code in production”. Internally we call this Mean Time To Release to emphasize that the new code is waiting to be released.
Mean Time To Release is still the metric we care about most long-term; however, we realized Mean Time To Release was hard for us to focus on because releases took so much time for an engineer to do. We decided that as a prerequisite, we needed to optimize for another metric first: Mean Time Between Release Start and Release End. We started tracking the actual clock time to complete a release from when an engineer sat down to do one.
This is a summary of our progress against the metric, Mean Time Between Release Start and Release End as we cut this time from 10 hours to 10 minutes:
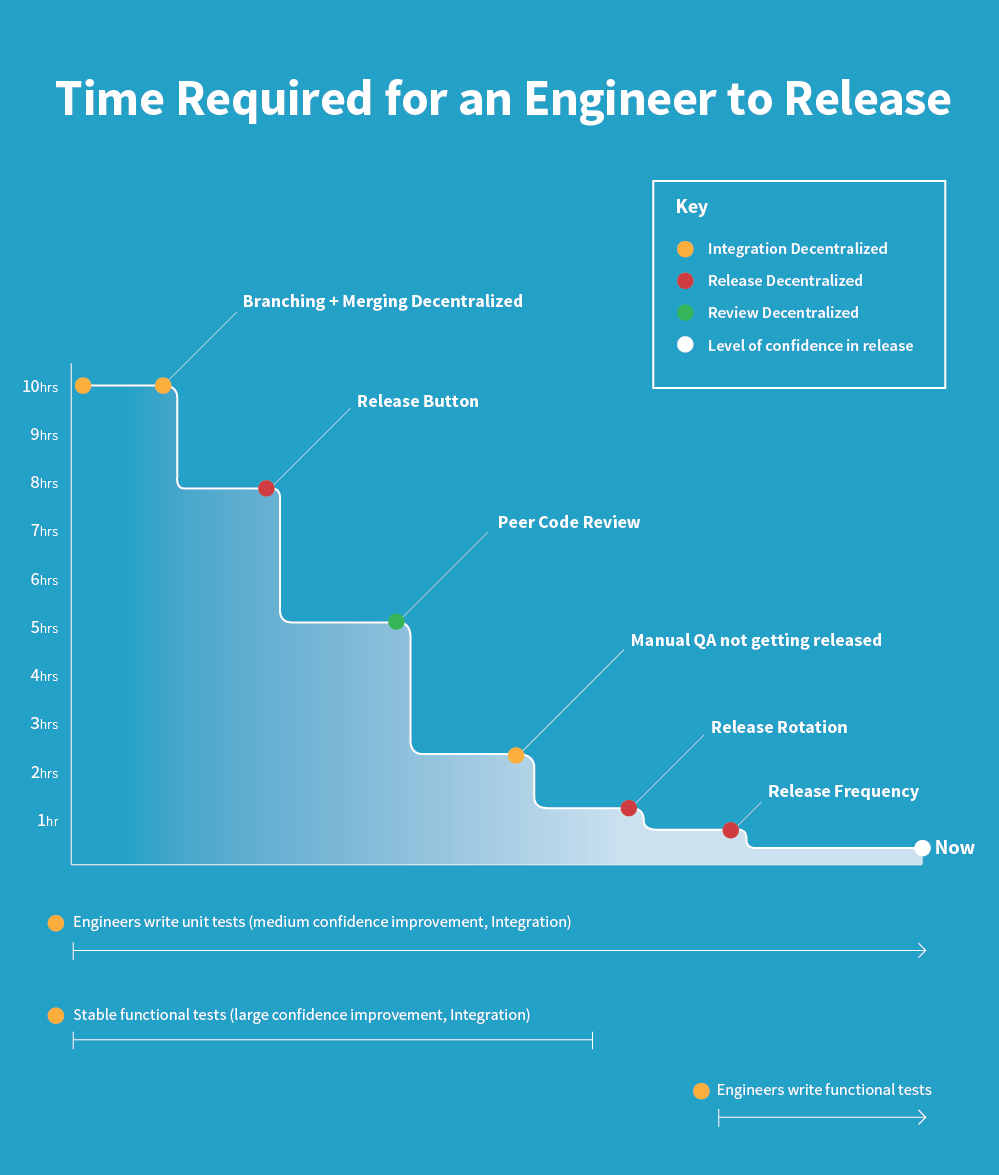
Each of the improvements targeted either Mean Time Between Release Start and Release End or increasing our confidence in our release process. As you see in the timeline above, these two streams of work happened largely in parallel. Below we break out each step and how much time it saved us.
Speed improvements #
Branching and Merging Decentralized #
Speed increase: 2 hours
Under our previous branching process, engineers would take a feature branch off of a development branch and our Release Manager would integrate those changes into a release branch to be released and merged with master. We shifted to GitHub Flow where each engineer takes feature branches off of master and integrates them into master after code review. This cut release time by distributing the job of integration to all engineers instead of one Release Manager.

Release Button #
Speed increase: 3.5 hours
Our CEO (previously the COO of Etsy) connected us with the Operations team at Etsy early in our continuous delivery thinking. The biggest piece of advice they had for us was to:
Create a release button.
Start pressing it more and more often.
Fix any problems that come up. Repeat.
We did exactly that. We started by creating a release button and only letting our Release Manager press it. Creating our release button required:
Building a site to host it and the associated scripts.
Pushing code from Github to our servers. DeployBot has helped us out a lot here.
Automating tasks like moving Trello cards and emailing our team about what got released.
Here’s a screenshot of our current release dashboard including the release buttons per environment:
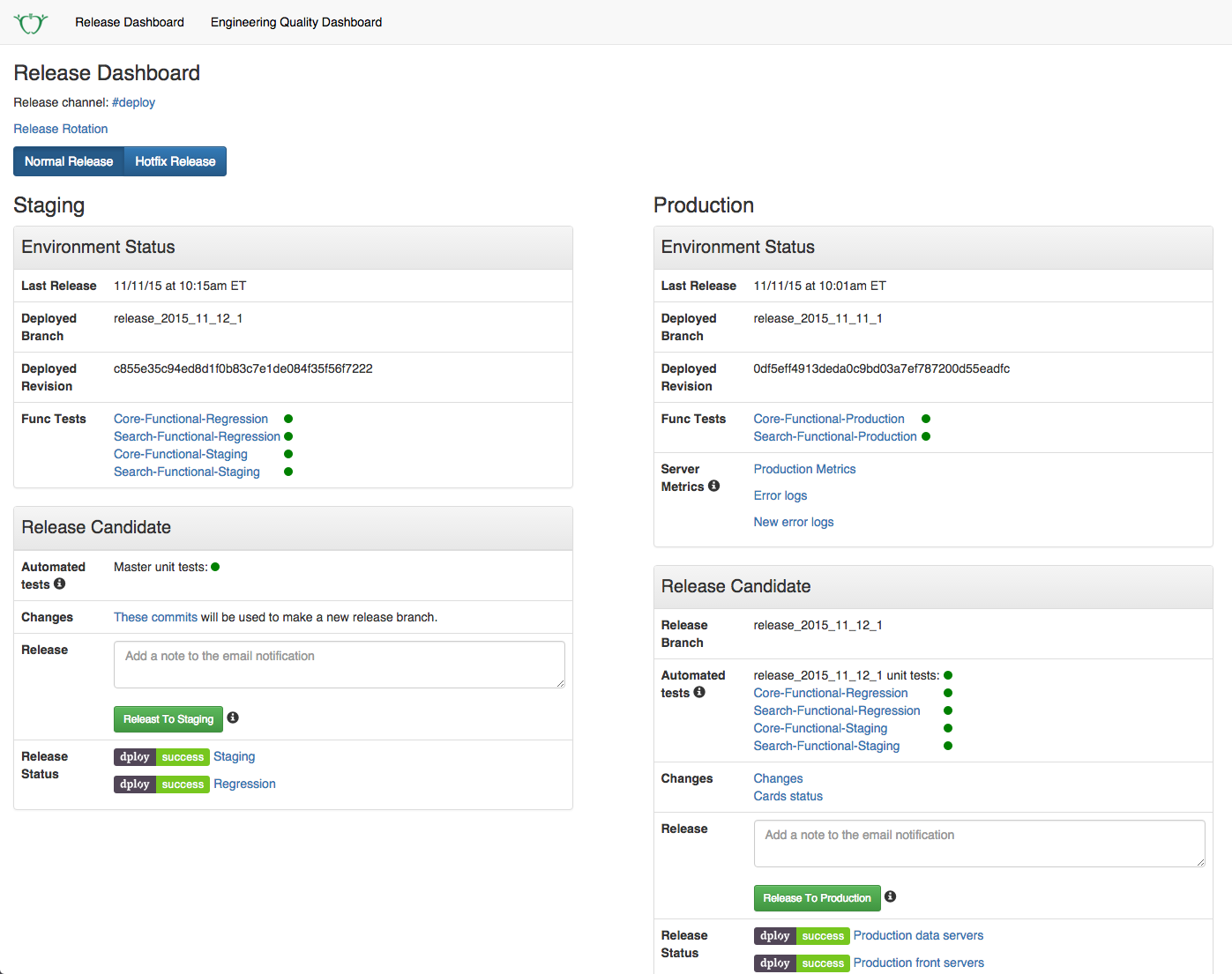
Peer Code Review #
Speed increase: 2.5 hours
Previously, we had two layers of code review. Engineers would do basic code reviews of each other’s code, but we depended on our Release Manager to reviewed all code more than anything else. After coming up with a list of guidelines for what to watch out for and how to give code reviews, we’ve distributed code reviews to all engineers on the team. Ideally, each pull request tags two other engineers for review: one who knows the area you’re working in well and one who doesn’t.
Manual QA not gating release #
Speed increase: 1 hour
Because of the parallel improvements in confidence we made (see below), we were able to remove manual QA from gating the release process. Now when we build features, fix bugs, or refactor, by default it goes to production without manual QA review. If an engineer has concerns or thinks they might be introducing problems, they can re-insert manual QA as gating for that work as needed.
We saw a decent speedup in Mean Time Between Release Start and Release End because of this, but systemwide, the confidence measures we introduced let engineers know of quality issues earlier and prevented time-consuming back-and-forth with manual QA. Being able to introduce this has been our largest speedup in Mean Time To Release to date.
Release Rotation #
Speed increase: 20 minutes
When we had worked most of the known kinks out of our release button, the Release Manager showed other engineers where to go to press the button, and we started rotating release responsibilities to a new engineer every week. By exposing the process to more people, we get a lot of feedback on the release process and tooling. This has helped us even further cut the time taken to release. Specifically, the largest speed gains here came as we provided tools to help the release person detect and correct potential problems with new code ready to be released.
Release Frequency #
Speed increase: 30 minutes
We had been releasing two times per week when release management was a full-time job for one person. Now we’re releasing eight times per week and release management takes ~1 hour over the course of a whole week. Because we’re releasing more frequently, there’s less to cover in each individual release, making each individual release take less time.
Confidence improvements #
We were spending a lot of time cycling back-and-forth between manual QA and engineering due to our lack of automated quality control measures. To release confidently, we did the following in parallel to our speed improvements. It worked well enough that we were able to remove manual QA from gating production releases (see above) and significantly shaped our thinking on The Fear of Breaking Things.
Engineers write their own unit tests #
Previously, we didn’t have many unit tests. After a bit of education on how to write testable code and how to write unit tests, engineers began writing their own unit tests for new functionality. They also wrote tests for uncovered code as they touched code related to those areas. Using this approach, we’ve gone from 0% to 53% coverage over 6 months.
Stable functional tests #
Previously, only two engineers on our team knew how to read the output of functional tests. In our CI tool, every time the functional tests ran, there were errors. Those two engineers had encoded knowledge in their brain to know when the errors were serious enough to pay attention to.
We wanted to trust these tests to let us know if we were clear to release by quickly looking at their status. To increase their trustworthiness, we began aggressively fixing broken tests and pushing flakey tests down into our more stable unit testing layer. This adds to our efforts to reshape our testing strategy to conform more to the test pyramid.
Engineers write their own functional tests #
We’re actively working on making it easier for engineers to write lightweight functional tests. These tests mimic the happy path a user would take through the system and sometimes one major error case. In addition to increasing confidence in our releases, it helps engineers test their own functionality quickly while building it.
What’s next #
During this whole process, we’ve focused on improving how quickly an engineer can release code (Mean Time Between Release Start and Release End). Now releases happen effortlessly enough that we can optimize for Mean Time To Release, the time that it takes for a specific piece of code to make its way to production. When we started, our Mean Time To Release averaged ~200 hours (clock time, not person time) and has decreased down to ~60 hours if you include time to code review.
As we optimize for Mean Time To Release, we’ll need to pay close attention to:
Code review becoming a gating factor for releasing
The distinction of code release and feature rollout to users (especially as it relates to feature flags)
Automated unit and functional test speed
Functional tests flakiness
As we move forward, we’ve started collecting feedback on what other companies find as bottlenecks in their release process. What’s the biggest bottleneck you’ve seen?